
Introduction
De par mon occupation principale, j’ai l’occasion de donner environ une cinquantaine d’interviews par an sur le sujet des nouvelles technologies. Ce billet doit donc commencer par un aveu : chaque fois que l’on m’a interrogé sur l’intelligence artificielle, j’ai levé les yeux au ciel. Bien sûr, le domaine du machine learning faisait des progrès et connaissait déjà plusieurs applications pratiques. Mais pour moi, « IA » était avant tout une étiquette que des départements markétings sans inspiration collaient à tout va sur n’importe quel produit qui calculait à un moment ou un autre une moyenne arithmétique.
Et pourtant, 2022 a été l’année de l’IA. La révélation, pour moi, est venue lorsque j’ai essayé DALL-E 2 (et peu après, MidJourney). Ces deux projets, qui permettent de générer des images à partir de descriptions textuelles1L’image d’en-tête de cet article est un exemple d’une telle image, générée avec MidJourney., ont déjà provoqué des remous importants dans le monde de l’art. Puis, en décembre dernier, ChatGPT a déferlé sur le monde. Pour faire simple, ChatGPT est un chatbot. Je suppose que la plupart d’entre vous l’ont déjà essayé à ce stade, mais si ce n’est pas le cas, je vous y invite fortement. Les mots ne peuvent pas rendre justice à la rupture qu’il représente. Il est difficile de se faire une idée de ce qui vient si on ne l’a pas essayé soi-même.
Vous avez peut-être lu que MidJourney remporte des compétitions artistiques, ou que des romans générés par ChatGPT innondent Amazon. L’artiste en vous a peur. Cet article est là pour vous inviter à ne pas se tromper d’ennemi.
Modèles linguistiques
Pour reprendre les mots d’Arthur C. Clarke, « toute technologie suffisamment avancée est indiscernable de la magie ». J’aime la façon dont la technologie peut parfois susciter ce sentiment d’émerveillement dans nos vies, mais ce sentiment est malheureusement source d’obstacles lorsque nous tentons de réfléchir aux implications ou aux limites d’une nouvelle avancée. Pour les besoins de cet article, nous devons d’abord prendre le temps de comprendre comment ces technologies fonctionnent sous le capot.
Commençons par ChatGPT. Il s’agit d’un modèle de langage ; en d’autres termes, c’est une représentation de la langue. Comme c’est le cas pour l’écrasante majorité des projets de machine learning, personne ne sait vraiment comment ce modèle fonctionne (pas même OpenAI, son créateur). Nous savons comment le modèle a été créé, mais il est bien trop complexe pour être appréhendé de manière formelle. ChatGPT, qui est le plus grand modèle de langage (public ?) à ce jour, compte plus de 175 milliards de paramètres. Pour comprendre ce que cela signifie, imaginez une machine géante qui possède 175 milliards d’interrupteurs que vous pouvez mettre dans une position ou une autre. Chaque fois que vous envoyez du texte à ChatGPT (par exemple, « écris le plan de markéting 2023 pour Le Chant du Cygne stp frérot »), ce texte est converti en position pour chacun de ces boutons. Et ensuite, la machine produit un résultat (davantage de texte) en fonction de leur position. Il y a également une part d’aléatoire, afin de s’assurer que la même question n’aboutira pas toujours à la même réponse (mais cela peut aussi être modifié).
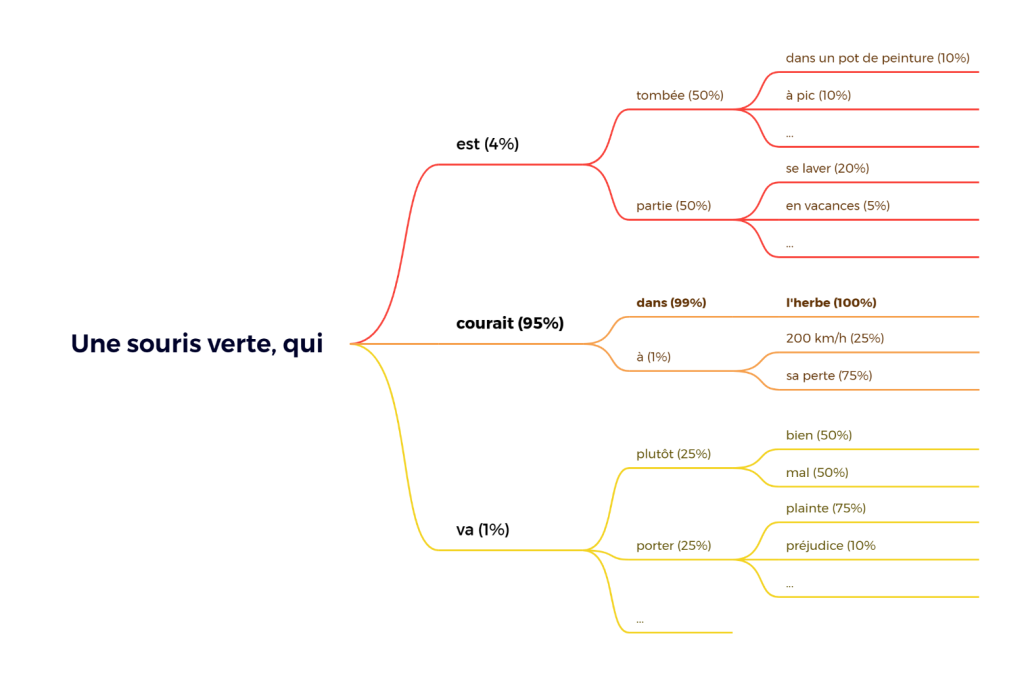
C’est la raison pour laquelle nous voyons ces modèles comme des boîtes noires : même si vous deviez passer votre vie à étudier la machine, il est peu probable que vous puissiez un jour comprendre la fonction d’un seul bouton (sans parler de tous les boutons). Pourtant, nous savons ce que fait la machine parce que nous connaissons la méthode qui l’a engendrée. Un modèle de langage est un algorithme capable de traiter du texte, et celui-ci en a reçu beaucoup pendant sa phase d’apprentissage : tout Wikipédia, des centaines de milliers de pages web, des livres, etc. L’étude de tous ces textes a permis la création d’un modèle statistique qui connaît la probabilité qu’un mot en suive un autre2Dans le cas de ChatGPT, il y avait en pratique une étape supplémentaire, appelée « renforcement supervisé ». Des « dresseurs d’IA » humains ont participé à de nombreuses discussions avec le robot et ont signalé toutes les réponses jugées problématiques (inexactes, partiales, racistes, etc.) afin que le modèle apprenne à ne pas recommencer.. Si je dis « une souris verte, qui », vous pouvez deviner avec un degré de confiance relativement élevé que la suite sera « courait ». Voilà, en quelques mots, comment fonctionne le ChatGPT. Pour un modèle de langue, finir votre phrase ou deviner quelle séquence de mots vient probablement après votre question revient exactement au même.
Si le terme d’IA demeure flou pour vous, classez-le dans la catégorie « mathématiques » ou « statistiques » : l’objectif de ces modèles est la prédiction. Lorsque nous utilisons ChatGPT, on peut nourrir le sentiment que l’IA « sait » des choses, puisqu’elle est capable de renvoyer des informations précises, contextualisées et adaptées aux requêtes qu’elle voit pour la première fois. Mais elle ne comprend en réalité pas le sens des mots : elle se contente de générer plus de texte qui « semble » être une suite naturelle de ce que l’utilisateur a envoyé.3Cela explique pourquoi ChatGPT peut dérouler des arguments philosophiques complexes, mais échoue lamentablement sur des questions d’arithmétique de base : il est plus difficile de prédire le résultat d’un calcul que le prochain mot d’une phrase. Elle n’a pas non plus de mémoire : son entraînement s’est achevé en 2021 et le modèle est statique. Les mises à jour se feront sous la forme de nouveaux modèles (par exemple, GPT-4 en 2024) formés sur de nouvelles données. En fait, ChatGPT ne se souvient même pas des conversations que vous avez avec lui : l’historique des conversations récentes est envoyé avec tout nouveau texte que vous tapez afin de rendre le dialogue plus naturel — en fait, ChatGPT n’a même pas conscience de quelle tirade vient de lui ou de vous.
La question de savoir si cela peut encore être qualifié « d’intelligence » (et si celle-ci est significativement différente de l’intelligence humaine) fera l’objet de débats philosophiques passionnants dans les années à venir. Après tout, on prête de l’intelligence à un enfant de 6 ans qui peut dire « j’espère qu’il fera beau demain » sans avoir la moindre compréhension du concept d’espérance (mais parce qu’il a compris que les mots s’utilisaient ainsi).
Modèles de diffusion
Les outils de génération d’images comme MidJourney et DALL-E sont basés sur une autre catégorie de modèles. Leur entraînement, bien sûr, se concentre sur la génération d’images (ou ensemble de pixels) au lieu de texte. Deux éléments sont en fait nécessaires pour générer une image à partir d’une description textuelle, et le premier tombe sous le sens. Le modèle a besoin d’un moyen d’associer des mots à des informations visuelles, il est donc alimenté par des collections d’images accompagnées de leur description. Comme dans le cas de ChatGPT, nous nous retrouvons avec une machine géante et impénétrable, cette fois-ci très douée pour associer des images à des données textuelles. La machine n’a aucune idée de ce à quoi ressemble le visage de Brad Pitt, mais si elle a vu suffisamment de photos de lui, elle sait qu’elles ont toutes des propriétés communes. Et si quelqu’un soumet une nouvelle photo de Brad Pitt, le modèle est capable de la reconnaître et de dire « yep, c’est bien lui ».
La deuxième partie, que j’ai trouvée plus surprenante, est la capacité d’améliorer la qualité d’une image. Pour cela, on utilise un « modèle de diffusion », entraîné sur des images nettes auxquelles on ajoute progressivement du bruit jusqu’à les rendre méconnaissables.

Cela permet au modèle d’apprendre la correspondance entre une image floue ou de mauvaise qualité et son homologue en haute résolution — là encore, à un niveau statistique4Il existe en effet des produits dédiés, basés sur l’IA, qui permettent d’affiner les vieilles photos ou d’en augmenter la résolution.. En mettant tous les morceaux ensemble, nous sommes en mesure de synthétiser des images : on part d’un bruit aléatoire (vous pouvez imaginer de la neige sur un vieux téléviseur) et nous « l’améliorons » progressivement tout en nous assurant qu’il adopte peu à peu les propriétés statistiques qui correspondent à la demande de l’utilisateur.5Vous pouvez trouver une description beaucoup plus détaillée du fonctionnement interne de DALL-E ici.
Les mauvaises questions
L’émergence de tous les outils mentionnés dans cet article a suscité de vives réactions de la part du public, certaines très négatives. L’irruption brutale de l’IA dans nos vies suscite des inquiétudes réellement légitimes, mais à mon avis, une grande partie du débat actuel se concentre sur les mauvaises questions. Abordons d’abord ces questions, avant de passer à ce qui, selon moi, devrait être au cœur de la discussion sur l’IA.
DALL-E et MidJourney volent le travail des vrais artistes
À quelques occasions, j’ai vu ces outils décrits comme des programmes qui font des patchworks d’images déjà vues, puis appliquent des sortes de filtres qui leur permettent d’imiter le style de l’artiste demandé. Il en découlerait que ces outils constituent un plagiat à l’échelle planétaire. Quiconque défend une telle sottise ignore les réalités techniques des modèles sous-jacents (dans le meilleur des cas), ou fait preuve de mauvaise foi.
Comme expliqué ci-dessus, le modèle est totalement incapable d’extraire des images (ou même des formes simples) des travaux sur lesquels il est entraîné. Le mieux qu’il puisse faire est d’extraire des caractéristiques mathématiques.

Il est indéniable que de nombreuses œuvres protégées par le droit d’auteur ont été utilisées au cours de la phase d’entraînement sans le consentement explicite des auteurs originaux, et il y a peut-être matière à discussion à ce sujet. Mais il convient également de souligner que les artistes humains suivent exactement le même processus pendant leurs études : ils copient les tableaux des maîtres et s’inspirent des œuvres qu’ils rencontrent. Et qu’est-ce que l’inspiration, sinon la capacité à saisir l’essence d’une œuvre d’art combinée à la volonté de la réexplorer ?
DALL-E et MidJourney présentent une avancée dans le sens où ils sont théoriquement capables de s’inspirer de toutes les œuvres produites durant l’histoire de l’humanité (et, probablement, de toutes celles qui seront produites à partir de maintenant), mais il s’agit d’un changement d’échelle uniquement — pas de nature.

L’IA rend les choses trop faciles
Cette critique implique généralement que l’art doit être difficile. Cette notion m’a toujours surpris, car l’observateur d’une œuvre d’art n’a généralement qu’une idée très limitée de l’effort (ou du peu d’effort) qu’elle a nécessité. Ce n’est pas un débat nouveau : des années après la sortie de Photoshop, un certain nombre de personnes continuent d’affirmer que les œuvres numériques ne sont pas véritablement de l’art. Ceux qui ne partagent pas cet avis rétorquent qu’utiliser Photoshop requiert beaucoup de compétences, et je crois que les deux camps passent à côté de la question. Robert Rauschenberg a-t-il dû faire l’étalage d’une grande virtuosité technique pour mettre de la peinture blanche sur une toile vierge ? Combien d’années de pratique musicale faut-il avant de pouvoir interpréter le fameux 4’33 » de John Cage ?
Même si nous devions introduire la compétence comme critère nécessaire de l’art, où serait la frontière ? Quel effort est un effort suffisant ? Lorsque la photographie a été inventée, Charles Baudelaire l’a décrite comme le « le refuge de tous les peintres manqués, trop mal doués ou trop paresseux pour achever leurs études » (et il n’était pas le seul à le penser, la citation complète ne tarit pas de venin). Il s’avère qu’il avait tort.
Il n’y a pas de retour en arrière possible
Peu importe ce que vous pensez de tous ces outils basés sur l’IA qui ont été lancés en 2022, sachez que d’autres arrivent. Si vous pensez que le domaine sera réglementé avant qu’il ne devienne incontrôlable, détrompez-vous : nos décideurs semblent bien plus enclins à investir dans le domaine qu’à le réguler — pour eux, c’est maintenant ou jamais, d’ici quelques années le pays sera irrémédiablement distancé. Pour les individus qui comptent dans ce débat, dans le monde politique, dans l’industrie, il n’existe aucune raison rationnelle de ralentir le mouvement.
La quatrième révolution industrielle

L’IA entraînera, a probablement déjà entraîné, des gains de productivité. Il est encore difficile d’imaginer leur ampleur. Si votre travail consiste à produire des textes semi-inspirés, vous avez des raisons légitimes de vous inquiéter. Cela vaut également pour les artistes travaillant sur commande : il y aura toujours des clients qui voudront une touche humaine, mais la plupart choisiront l’option bon marché. Et ce n’est pas tout : les développeurs, avocats, enseignants, médecins et bien d’autres encore doivent s’attendre à ce que leur travail change en profondeur.
Il faut garder à l’esprit que ChatGPT est un chatbot polyvalent. Dans les années à venir, des modèles spécialisés émergeront et surpasseront ChatGPT sur des domaines métiers spécifiques. En d’autres termes, si ChatGPT est incapable de faire votre travail à l’heure actuelle, il est probable qu’un produit qui sortira dans les cinq prochaines années le pourra. Nos emplois, tous nos emplois, consisteront à superviser les IA et à s’assurer que leurs résultats sont corrects plutôt que de les chercher nous-mêmes.
Il est possible que l’IA se heurte à un mur de complexité et ne progresse pas davantage, mais après m’être trompé à plusieurs reprises, j’ai appris à ne pas parier contre ce domaine. L’IA va-t-elle changer le monde autant que la machine à vapeur l’a fait6Au début du 19e siècle, de nombreux travailleurs agricoles ont été remplacés par des machines, ce qui a donné lieu à un important exode rural. Dans ce Nouveau Monde, l’achat de machines coûteuses devenait plus important que la possession de vastes parcelles de terre ou de serfs. La révolution industrielle a joué un rôle majeur dans le déclin du féodalisme en Europe et l’émergence du capitalisme. ? Nous devrions espérer que non, car les changements brutaux des moyens de production modifient la structure de la société humaine, et ces transformations se font généralement dans le sang.
Biais et propriété de l’IA
Suffisamment de choses ont été dites sur les biais des IA pour que je n’y revienne pas. Un sujet plus intéressant est la façon dont OpenAI lutte contre ces biais. Comme mentionné ci-dessus, ChatGPT est passé par une phase d’apprentissage supervisé où le modèle de langage apprend essentiellement à ne pas être un vieux réac ». Bien qu’il s’agisse d’une caractéristique souhaitable, on ne peut s’empêcher de remarquer que ce processus remplace des préjugés par d’autres. Les conditions de cette phase de mise au point sont opaques : qui sont les soldats inconnus qui signalent les « mauvaises » réponses ? Des travailleurs sous-payés dans des pays du tiers-monde, ou des ingénieurs de la Silicon Valley sous acide ? (Spoiler : les premiers).
Il est également utile de rappeler que les produits d’IA ne travailleront pas pour le bien commun. Les différents produits conçus à l’heure actuelle appartiennent à des entreprises qui seront toujours guidées, avant tout, par la recherche de profits ; l’intersection entre ces profits et le bien commun demeurant hautement aléatoire. Tout comme un changement dans l’ordre des résultats de recherche de Google a un effet mesurable sur les gens, les compagnons ou assistants IA exerceront une influence subtile sur leurs utilisateurs. Des efforts markéting titanesques seront déployés pour nous convaincre que ces modèles sont des technologies neutres. Ce n’est jamais le cas.
Et maintenant ?
Puisque la question ne semble plus être de savoir si l’IA va entrer dans nos vies, nous devrions au moins discuter de la manière dont nous pouvons nous y préparer.
En premier lieu, soyons vigilants à ce que ChatGPT (ou de l’un de ses descendants) ne se retrouve jamais dans une position où il prend des décisions non supervisées : il s’agit d’un outil extrêmement doué pour afficher de la certitude, mais il commet encore de nombreuses erreurs factuelles. Par nature, il est difficile d’imaginer comment cela pourrait cesser d’être le cas. Mais la tentation de réduire les coûts sera très forte, et je suis prêt à parier que la part d’humains impliqués dans la majorité des tâches va graduellement décroître.
Je prédis également qu’au cours de la prochaine décennie, la majorité des contenus disponibles en ligne (d’abord les textes et les images, puis les vidéos et les jeux vidéo) seront produits par des IA. Je ne pense pas qu’il faille trop compter sur un repérage automatique fiable de ces contenus. Si vous trouviez que l’humanité ne parvenait pas à gérer l’afflux de fake-news sur les réseaux sociaux, vous n’êtes pas au bout de vos peines. Nous devrons nous montrer critiques à l’égard de ce que nous lisons en ligne et traverser dix fois plus de bruit. Par-dessus tout, je redoute les modèles spécialisés qui se profilent à l’horizon. Que se passera-t-il lorsque l’un des Big Four entraînera un modèle avec le code des impôts et posera des questions d’optimisation fiscale ? Quand quelqu’un de l’armée jouera avec ChatGPT et dira : « ouais, mettez-m’en dans mes drones » ?
La révolution des IA commence : elles prendront en charge de nombreuses tâches ennuyeuses, mettront de nouvelles capacités à la portée de tous et ouvriront la porte à de toutes nouvelles formes d’art (oui). Mais l’IA sera aussi une catastrophe. Si on se fie à l’histoire, elle entraînera une concentration accrue du pouvoir et nous poussera plus loin sur la voie du technoféodalisme. Elle changera la façon dont le travail est organisé et peut-être même notre relation à la connaissance. Et nous n’aurons pas notre mot à dire.
La boîte de Pandore est ouverte.